eXtremeDB SQL Product Overview
eXtremeSQL is implemented in the C library
libmcosql. C and C++ developers link these libraries directly into their applications and can use the C language API functions, such asmcosql_execute_query()andmcosql_execute_statement(),or the rich set of C++ classes, such as McoSqlEngine for executing SQL statements and queries and QueryResult for processing result sets. The Java, C# and Python APIs also support SQL through classes SqlLocalConnection, SqlRemoteConnection and SqlResultSet.In addition the highly configurable command-line utility xSQL is provided to allow for development and testing of SQL scripts, either interactively or via SQL script files, on eXtremeDB databases with all possible options, including MVCC or MURSIW transaction managers, debug or release libraries, eXtremeDB High Availability and eXtremeDB Cluster. The Quick Start Tutorial provides examples demonstrating the use of xSQL.
Operational Overview
The following diagram illustrates the eXtremeSQL application structure and operational flow:
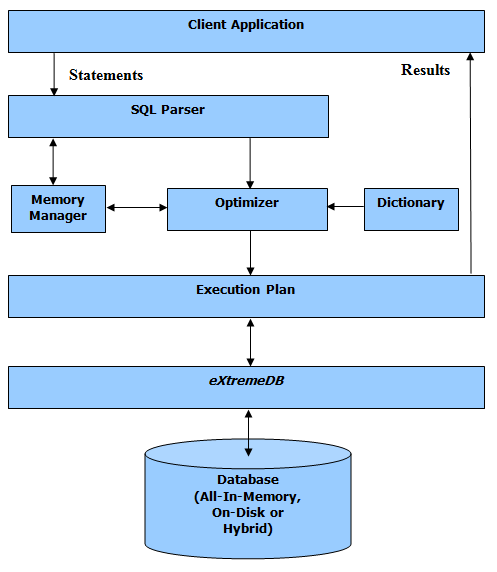
This diagram depicts the major operational steps and elements of eXtremeSQL. SQL statements are embedded within application code and submitted to eXtremeSQL through the APIs mentioned above. The SQL statements are parsed to verify their syntactical correctness. Then, if no errors are found, the optimizer is invoked. The optimizer attempts to determine the most efficient means of processing the statement by interrogating the database dictionary to discover potential indexes and autoid/reference relationships between classes. This step results in an execution plan that identifies the procedural steps eXtremeSQL will take in producing the result set. (e.g., locate an object of class X by the index on field A; use the value of field B of the found object as a search value on indexed field D of class Y, and so on.).
After the statement has been parsed, optimized, and an execution plan formed, the database is updated or queried.
eXtremeSQL Processing
Most commonly, eXtremeSQL statements are embedded in C, C++, Java or C# within a single-threaded application by instantiating an engine object and calling its execute method. However, multiple processes can simultaneously access a database in shared memory, or two or more threads within a single process can simultaneous access an in-memory or disk-based database using the engine.
The number of concurrent threads accessing the database through eXtremeSQL should be considered carefully. The nature of any dynamic SQL implementation is that it requires fairly extensive use of dynamic memory allocation, for holding tokens during parsing, for temporary results during execution, and miscellaneous other uses. It is prudent to restrict the number of tasks (threads) simultaneously processing SQL to keep memory consumption within reasonable bounds.
In eXtremeSQL version 6.5 or later a number of significant enhancements were implemented that address performance issues for complex SQL statement processing.
Specifically:
- dynamic memory allocation that was previously occurring during statement compilation and building the execution plan has been replaced with static memory “block” allocation
- “materialization” takes place only when necessary for sort and aggregation operations
- the eXtremeSQL C++ and C APIs have been slightly modified to reduce the number of virtual and indirect calls, and use arrays instead of iterators where possible
- database metadata is shared between sessions to avoid caching
- a reference to the current memory allocator is used to eliminate the use of thread-specific memory.
eXtremeSQL Query Optimization
Creating the optimal plan for execution of SQL statements is a very complex and challenging task. SQL optimizers analyze SQL queries sent to the database and select the best search strategies for accessing the database.
There are two classes of SQL optimizers: cost-based and rule-based. Disk-based database systems generally use a cost-based optimizer. With cost-based optimizers, query optimization greatly depends on data distribution. Often, optimizers take samples and use statistics provided by the database engine, and collect statistical information themselves, to calculate the cost of candidate execution plans. Building optimal plans is CPU-intensive and inherently unpredictable; the amount of time spent in the optimizer varies from query to query and execution plans can change from one invocation to another as the distribution of data changes.
To provide faster and more deterministic performance, eXtremeSQL uses a rule-based optimizer that enables the developer to specify query execution plans within an application. For example, the optimizer never reorders tables in the query: the joins are performed in the sequence the tables were specified. Some of the other key rules that are used for query optimization include:
- If possible, an index is used.
- Each table is assigned an ordinal number representing its position in the
FROMlist.- The search predicate is divided into the set of conjuncts and the conjuncts are sorted. Therefore the expressions accessing the tables with smaller ordinal numbers are checked first.
- The execution of subqueries is optimized by checking the dependencies of the subquery expression. The results of the subquery are saved and recalculated only if the subquery expression refers to fields from the enclosing scope.
For more information about query optimization in eXtremeSQL, see the Optimizing Query Performance page.