Using the eXtremeSQL Distributed SQL Engine
The eXtremeSQL Distributed SQL Engine provides limited support for the database sharding architecture for eXtremeDB Cluster installations. Why is it limited? Most full-blown distributed database engines (such as the one found in Oracle for example) normally create an execution plan based on the query tree and data distribution statistics (or other knowledge of how the data is distributed between shards), that contains “map-reduce” style operations. The eXtremeSQL distributed engine merely executes the query on every node over that node's shard, and consolidates the result sets received from multiple nodes when possible (the consolidation of the results is referred to as merge).
Sometimes merging the result sets is simply impossible, as it is for example for calculating an average. More often, the engine does not have enough information to make sure that the combined result set is correct. The Distributed SQL Engine takes the most optimistic approach -- it always assumes that the application distributed data between shards and created the SQL query to avoid merging problems.
Yet with the understanding of the engine's limitations, many application's will benefit from using the distributed engine and improve their overall database access performance dramatically.
The Distributed SQL Engine sends a query to one of the network nodes, or broadcasts queries to all nodes. A node is specified through the query prefix. In order to control the distribution of data, the application must either load data to each shard locally, or specify the node ID (number) in the
insertstatements. For example:
10:insert into T values (...)
Also the application can explicitly use the current node ID in the
selectcondition when selecting out records that are inserted on the specific node (%#indicates the current node ID, and%@the number of shards). For example:
insert into hist_cpvehicleid_jj select * from foreign table (path='/home/usr/shea2.csv', skip=1) as hist_cpvehicleid_jj where mod(hashcode(fstr_vechileid), %#)=%@;
If none of those methods are used, the Distributed SQL Engine broadcasts the insert on all nodes. The following query types are supported:
select * from T; *:select * from T; -- similar to the above, run the statement on all nodes N:select * from T; -- execute the statement on the node N (nodes are enumerated from 1) ?:select * from T; -- execute the statement on any node. SQL picks up the node in the round-robin fashion, thus implementing a simple load-balancing scheme
Note that, normally, the
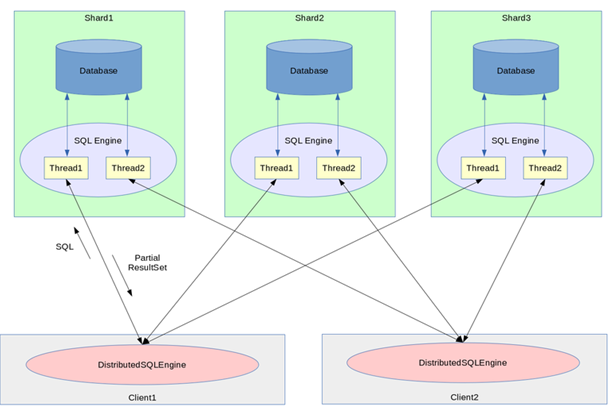
select,updateanddeletestatements are executed on all nodes, while theinsertstatement adds a record to only one of the shards. Once the query has been executed and the result set is created on each node, the Distributed SQL Engine collects the resulting data sets from all nodes. If the query contains an aggregation or sort clause, orsequencefunctions (statistical functions operating on fields of typesequence), then the result sets are merged.The following diagram illustrates data flow implemented by the Distributed SQL Engine. Note that the rectangles --
shard1,shard2,shard3,client1andclient2, can be placed on the physical different hosts or on the same host, or in any combination. For exampleshard1,shard2,client1on one physical node andshard3andclient2on another physical node.
Aggregates
The Distributed SQL Engine currently supports the following aggregates:
COUNTMINMAXSUM(aggregate operand is a column) with or without a 'group by' clauseThe engine does not currently support:
- Merging aggregates with the
DISTINCTqualifier;- Aggregates over complex expressions (such as
X+Y), except if thesortby orgroup bycolumns are included into the result set or theselectstatement;For instance (using
Metatableas an example):select Metatable.*,FieldNo+FieldSize as ns from Metatable order by ns;or
select T.*,x+y as xy from T order by xy;
- Aggregates over hash (
seq_hash_aggregate_*), except for two scenarios:
when the data that the hash table is built over belongs to a single shard (exchange in the example below):
select seq_hash_agg_sum(price,exchange) from Quote;
- if the sequence is converted into a horizontal representation --
flattened, the query can run regardless of the data distribution:select flattened seq_hash_agg_sum(price,exchange) from Quote;
- The
AVGaggregate. Unless the groups from different nodes do not overlap. For example the following layout is supported:Node1: Symbol Price AAA 10.0 AAA 12.0 AAA 9.0 BBB 11.0 BBB 10.0 BBB 10.0 Node2: Symbol Price CCC 8.0 CCC 7.0 CCC 10.0 DDD 15.0 DDD 14.0 DDD 13.0 select avg(Price) from Quote group by Symbol;Other examples of valid and invalid statements are:
select * from T;Supported; the results are concatenated.
select * from T order by y;Supported; sort results from all nodes
select * from T order by x+y;Complex expressions are not currently supported
select sum(x) from T;Supported; the aggregated results are merged
select avg(x) from T;Merge of AVG aggregate is not currently supported
select y,sum(x) from T group by y;Supported; groups and aggregates are merged
select sum(x) from T group by y;Supported; note that the 'group by' columns must be included in the "from" list
select sum(x*2) from T;Complex expressions are not currently supported
select ifnull(sum(x), 0) from T;Supported; aggregate results are merged
select seq_sum(x) from T;Supported; results are merged
select seq_hash_agg_sum(x,y) from T;Merge of the hash aggregates are not currently supported
select flattened seq_hash_agg_sum(x,y) from T;Supported; sorted, split in groups and aggregated
Importing data
The Distributed SQL Engine supports definition for a sharding condition when data is imported from a
CSVfile or through application code. Sharding ofCSVimported data is specified through the following SQL statement:select from foreign table (path='csv-file', skip=n) as PatternTable where distribution-conditionThe distribution-condition contains:
- an
insert-into-selectstatement,- a
fromclause specifying the CSV filename,- an
asexpression specifying the table to insert into,- and a
whereclause specifying the destination node.As mentioned above, the Distributed SQL Engine also supports special
"%@" and "%#"pseudo-parameters. The first corresponds to the node number (zero based); the second is used to specify the total number of nodes. For example:echo "insert into table_name select * from foreign table (path='table_name_file.csv', skip=1) as table_name where mod(instrument_sid/$chunk_size,%#)=%@;" > loadrisk.sql ./xsql.sh loadrisk.sqlThe
xsql.shscript invokes the Distributed SQL Engine as follows:xsql @node1 @node2 ... @nodeN $@An application can read input data from a stream (a socket in the example below) or any other source, and insert it into the database through a code fragment similar to the following:
table_name tb; socket_read(s, &tb); engine.execute("insert into table_name(starttime, endtime, book1, book2, instrument_sid) values (%l,%l,%s,%s,%l)", tb.starttime, tb.endtime, tb.book1, tb.book2, tb.instrument_sid);The following code fragment would add a sharding condition to the application's code:
char sql[MAX_SQL_STMT_LEN]; table_name tb; socket_read(s, &tb); sprintf(sql, "%d:insert into table_name (starttime,endtime,book1,book2,instrument_sid) values (%%l,%%l,%%s,%%s,%%l)", tb.instrument_sid%n_nodes); engine.execute(sql, tb.starttime, tb.endtime, tb.book1, tb.book2, tb.instrument_sid);
Adding Shards at Runtime
Sometime it may be necessary to add a shard to an existing distributed network. For example, to go from 3 shards to 4. To do so all clients need to re-connect to the 4 shards. This necessitates closing the Distributed SQL Engine that is connected to the 3 shards and reconnect to all 4.
Moving or rebalancing the data is the application’s responsibility as there is no right way of automatically redistributing data across shards. Essentially it is necessary to pull data to a client and redistribute from that client.
One approach is to use a file to output data to. For example, output data from an xSQL client to an external file:
XSQL>format CSV XSQL>output mytable.csv SELECT * FROM MYTABLE
Now the file
mytable.csvis copied to all shards and inserted into the appropriate table(s):
XSQL>INSERT INTO MYTABLE from select * from foreign table (path='mytable.csv') where ...
Another possible approach is to use the following semantics to select data from the table
Tlocated on node 1 and insert it to the table T on the node 2:XSQL>create table foo(i integer, s varchar); XSQL>1:insert into foo values (1, 'one'); XSQL>1:insert into foo values (2, 'two'); XSQL>select * from foo; i s ---------------------------------------------------------------------- 1 one 2 two Selected records:2 XSQL>1:select * from foo; i s ---------------------------------------------------------------------- 1 one 2 two Selected records:2 XSQL>2:select * from foo; i s ---------------------------------------------------------------------- Selected records:0Now a new object is inserted into table foo on node2, then the contents of table foo on node1 are inserted on node 2 using the “
1>2” syntax and the results are displayed, first the aggregate from both nodes, then from the individual nodes:XSQL>2:insert into foo values (3, 'three'); XSQL>1>2:select * from foo; XSQL>select * from foo; i s ---------------------------------------------------------------------- 1 one 2 two 3 three 1 one 2 two Selected records:5 XSQL>1:select * from foo; i s ---------------------------------------------------------------------- 1 one 2 two Selected records:2 XSQL>2:select * from foo; i s ---------------------------------------------------------------------- 3 three 1 one 2 twoA Note on Conditions for Sharding
In order for applications to benefit from the horizontal partitioning of data (i.e. sharding) a few conditions should normally be met. First, the data itself ought to be large enough for the search algorithms to benefit from the reduced data size. Search algorithms integrated with the database runtime are very smart in that they employ indexes to minimize I/O. Generally speaking, even for a simple
treelookup to benefit from the reduced data sets, the data sets have to be on the order of tens of gigabytes. The performance of a simplehashindex algorithm is even less dependent on the database size.Second, the underlying hardware should provide the means to handle access to shards in parallel. Normally that means that access to each shard is handled by its own CPU core and that the I/O channels for each shard are separated (for example the shards are physically located on different machines). This way the lookup on each shard is truly executed in parallel. If shards are created on the same host, to achieve best results the number of shards should normally be equal to the number of real (not hyper-threaded) CPU cores and the storage media is organized in a
RAIDtype of layout.Sharding is not without cost. Although it is theoretically possible to utilize sharding from the native eXtremeDB APIs, in practice this is almost never done. The reason is that it is extremely difficult for applications to combine the result sets received from shards correctly and efficiently. The Distributed SQL Engine implements this functionality by creating execution plans, i.e. algorithms that are an integral part of the engine itself. Furthermore, the Distributed SQL Engine is capable of executing a large subset of SQL queries, but it is not the entire set of SQL that can be run against a local database. For example, for the Distributed SQL Engine to execute
JOINoperations, the data must be organized in a certain way that may require duplicating some data on all shards. Often the memory or media overhead imposed by the Distributed SQL Engine is quite large. Systems that have a lot of resources to spare to improve search performance are normally server-type setups with a large number of CPU cores, tens or even hundreds of gigabytes of memory and distributed physical I/O subsystems.The Distributed SQL Engine requires additional system resources such as memory, semaphores, etc., to provide efficient access to a distributed database. Those resources are normally not available in embedded environments. In our experience applications that run in the context of INTEGRITY OS, VxWorks OS on ARM or embedded MIPS CPUs or similar resource constrained setups never benefit from using distributed SQL. If a careful analysis of specific embedded system constraints and application requirements determines that the Distributed SQL Engine is desired, a custom distribution package can be built on request.
Support for Different Host Languages
In addition to C and C++, the Distributed SQL Engine can be used from Java, C# and Python.
Java
To create a Distributed connection in Java, simply instantiate a SqlRemoteConnection object by invoking the following constructor overload:
/** * Constructor of the distributed database connection. * @param nodes database nodes (each entry should have format "ADDRESS:PORT") */ public SqlRemoteConnection(String[] nodes, int maxAttempts) { engine = openDistributed(nodes); }For example, the following code snippet opens the Distributed SQL Engine for sharding on two nodes:
static String [] nodes = new String[]{"localhost:40000", "localhost:40001"}; SqlRemoteConnection con = new SqlRemoteConnection(nodes);Note, that runtime initialization is done in the Database class constructor, so a Database object must be created even if not used.
C# (.NET Framework)
To create a Distributed connection in C#, simply instantiate a SqlRemoteConnection object by invoking the following constructor overload:
/** * Constructor of the distributed database connection. * @param nodes database nodes (each entry should have format "ADDRESS:PORT") */ public SqlRemoteConnection(String[] nodes) { engine = OpenDistributed(nodes); }For example, the following code snippet opens the Distributed SQL Engine for sharding on two nodes:
static String [] nodes = new String[]{"localhost:40000", "localhost:40001"}; SqlRemoteConnection con = new SqlRemoteConnection(nodes);Note, that runtime initialization is done in the Database class constructor, so a Database object must be created even if not used.
Python
To create a Distributed connection using Python, open the module method connect with a
tupleas the first argument. For example:con = exdb.connect(('node1:5001', 'node2:5001', 'node3:5001'))Also one can create a SQL server using the Python wrapper. For example:
conn = exdb.connect("dbname") # pass engine, port and protocol buffer size. # Note that 64K is not enough if sequences are used server = exdb.SqlServer(conn.engine, 50000, 64*1024) server.start() # Non-blocking call ... # Do something else or just wait server.stop() # Stop server conn.close()
Using sharding with xSQL
To illustrate using the Distributed SQL Engine with xSQL, consider the following database schema (created via SQL):
create table Orders ( orderId int primary key, product string, customer string, price double, volume doulbe )And the following CSV data in file
order.csv:orderId|product|customer|price|volume 1|A|james|10.0|100 2|B|bob|50.0|200 3|A|paul|11.0|300 4|C|paul|100.0|150 5|B|bob|52.0|100 6|B|bob|49.0|500 7|A|james|11.0|100 8|C|paul|105.0|300 9|A|bob|12.0|400 10|C|james|90.0|200Create SQL servers
First, to create several databases and run SQL server on them, we use command-line parameters for xSQL as follows to create three instances of an in-memory database with size of
10 Mband start the SQL server listening on ports10001,10002and10003:./xsql -size 10m -p 10001 ./xsql -size 10m -p 10002 ./xsql -size 10m -p 10003Now we can connect to all three servers using the Distributed SQL engine as xSQL accepts the addresses of the servers as command-line options:
./xsql @127.0.0.1:10001 @127.0.0.1:10002 @127.0.0.1:10003Alternatively, we could specify the server addresses in a config file (
client.cfg) like:{ remote_client : [ "127.0.0.1:10001", "127.0.0.1:10002","127.0.0.1:10003"] }And invoke xSQL as follows:
./xsql -c client.cfgUsing xSQL interactive mode
After connecting to servers, xSQL goes to interactive mode. First we create a table on all nodes with command:
create table Orders (orderId int primary key, product string, customer string, price double, volume double);By default, the Distributed SQL Engine sends queries to all nodes. So the
create tablestatement will be executed by all three nodes. Next we can import and distribute the data across the servers using the following SQL statement:insert into Orders select * from 'order.csv' as Orders where mod(orderId, %#)=%@;The pseudoparameters '
%#' and '%@' refer to the total number of nodes and zero-based node ID. In our case '%#' equals to 3 and '%@' is 0 for the first server (running on port10001), 1 for the second server and 2 for the third server. For example, on the second server the statement will be equivalent to:insert into Orders select * from 'order.csv' as Orders where mod(orderId, 3)=1;and as a result inserts orders with ID 1, 4, 7 and 10. (Note that if you start SQL servers on different hosts, the file
order.csvmust be accessible on all hosts.)Now, to check the data, we select records from all nodes :
XSQL>select * from Orders order by orderId; orderId product customer price volume ------------------------------------------------------------------------------ 1 A james 10.000000 100.000000 2 B bob 50.000000 200.000000 3 A paul 11.000000 300.000000 4 C paul 100.000000 150.000000 5 B bob 52.000000 100.000000 6 B bob 49.000000 500.000000 7 A james 11.000000 100.000000 8 C paul 105.000000 300.000000 9 A bob 12.000000 400.000000 10 C james 90.000000 200.000000 Selected records: 10To select records from the second server only:
XSQL>2:select * from Orders; orderId product customer price volume ------------------------------------------------------------------------------ 1 A james 10.000000 100.000000 4 C paul 100.000000 150.000000 7 A james 11.000000 100.000000 10 C james 90.000000 200.000000To use
group byandorder bystatements:XSQL>select product, sum(price*volume) as s from Orders group by product; product s ------------------------------------------------------------------------------ A 10200.000000 B 39700.000000 C 64500.000000 XSQL>select customer, sum(price*volume) as s from Orders group by customer order by s; customer s ------------------------------------------------------------------------------ james 20100.000000 bob 44500.000000 paul 49800.000000
Using a Table Qualifier
Currently a distributed client application cannot use a table qualifier as a prefix in the
order byor thegroup bycolumn lists. For example, given a table Customer and a columnLastNamedefined with a schema like the following:class Customer { uint4 customerKey; string FirstName; string LastName; hash<customerKey> by_customerKey[500000]; }; class Facts { uint4 customerKey; double price; uint4 Quantity; tree<customerKey> by_customerKey; };The following
selectsyntax is not supported:SELECT customer.FirstName, customer.LastName, sum(facts.Quantity) as qty, sum(facts.price) as price, as sales FROM customer, facts GROUP BY customer.FirstName, customer.LastName ORDER BY customer.FirstName, customer.LastName;Nor is alternative syntax, like the following (using aliases) supported:
SELECT supplier.address as s_address, customer.address as c_address FROM supplier, customer ORDER BY s_address, c_address;Nor is the following (specifying the column number):
SELECT supplier.address, customer.address FROM supplier, customer ORDER BY 1, 2;