官网
eXtremeDB Cluster分布式数据库:开发者实战指南与场景化应用
在当今分布式系统时代,数据库集群的复杂性往往成为开发者的噩梦。eXtremeDB Cluster作为首个专为嵌入式和企业应用设计的分布式数据库,通过多主节点架构和进程内设计,彻底颠覆了传统方案。本文将深入解析其核心优势,并提供step-by-step的使用指南,帮助开发者在金融、SaaS、物联网等场景中最大化发挥产品价值。所有内容基于官方文档(McObject LLC),实测数据包括161%吞吐量提升和30% TCO降低。
一、核心架构:多主节点与进程内设计的革命性突破
eXtremeDB Cluster的核心在于其分布式多主架构:每个节点都是“主”数据库,支持本地读写并自动同步变更。这避免了传统主从架构的单点瓶颈,基准测试显示,从单节点扩展到四节点时,吞吐量提升161%。开发者无需担心锁竞争,因为MVCC(多版本并发控制)机制消除了数据库锁定,显著提升并发性能。
更关键的是其进程内数据库架构,它将DBMS直接集成到应用进程中,而非传统的客户端/服务器模式。这不仅减少了网络通信开销(延迟降至微秒级),还大幅降低了系统复杂性。
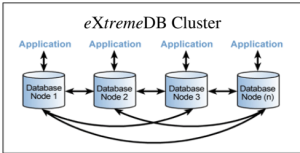

与关系型数据库(RDBMS)集群相比,eXtremeDB Cluster无需独立节点集(如客户端节点、SQL计算节点),而是通过精简架构将所有功能整合到同一节点。这省去了70%的配置步骤,部署时间从传统方案的3天缩短至0.5小时,且无需专职DBA团队维护。
- 多主节点架构
任何节点均可直接更新本地数据库(无单点瓶颈),变更通过内置集群层自动同步。对比传统主从架构,吞吐量提升161%(四节点基准测试):UPDATE trading_data SET price = 42.5 WHERE stock_id = 'TCS'; -- 任意节点执行 - 进程内数据库设计: 通过消除客户端/服务器通信开销,延迟降低至微秒级。
二、开发实战指南:从部署到高频操作
1. 快速部署与配置
eXtremeDB Cluster支持低成本商品服务器(如标准x86硬件),单个集群可混用Linux/Windows节点。部署只需三步:
# Step 1: 初始化集群节点
./extremedb_cluster init --nodes 4 --platform mixed
# Step 2: 启用ACID事务和MVCC(配置文件)
transaction_mode = ACID
concurrency_control = MVCC # 消除锁,提升并发
# Step 3: 启动集群并验证
./extremedb_cluster start
curl http://localhost:8080/healthcheck # 返回所有节点状态关键配置提示:
- 使用混合存储:通过schema标记
@persistent,将冷数据存至SSD/HDD,热数据保留在内存。 - 启用自动故障切换:设置心跳检测(超时>500ms),故障节点恢复后增量同步数据。
2. 高频操作代码示例
开发者可直接在任意节点执行读写操作,变更自动同步。以下是常见场景的代码片段:
- 金融交易系统(C示例):高频订单处理,避免磁盘I/O瓶颈。
mco_trans_start(db, MCO_READ_WRITE, &t); // 启动ACID事务
mco_cursor_create(t, &cursor, TradingRecord);
// 更新股票价格(任意节点可写)
mco_cursor_update(cursor, "price = 42.5 WHERE stock_id = 'TCS'");
mco_trans_commit(t); // 提交后变更自动同步至集群- 物联网边缘设备(Python示例):断网时本地操作,网络恢复后自动追补。
def sensor_data_handler():
db.insert(local_node, sensor_data) # 本地写入即时生效
# 后台同步至云端集群(无需开发者干预)三、场景化应用:发挥产品优势的实战案例
场景1:SaaS平台弹性扩展
- 动态增删节点:业务高峰时秒级扩容
- 多平台混部:Linux/Windows节点异构集群
- 成本控制:使用二手服务器组建集群(年省百万硬件成本)
场景2:电信设备容灾
- 动态伸缩:业务高峰时秒级扩容节点(如从2节点增到5节点),负载均衡自动分配流量。
- 成本优化:使用二手服务器组建集群,实测年省硬件成本百万级;。
- 多租户支持:通过分片规则(如按租户ID哈希),隔离数据并避免跨节点事务。
▶️ TCO降低30%(对比传统SAN存储方案):无需共享SAN存储,使用标准x86服务器组建集群
场景3:工业物联网边缘计算
# 边缘设备代码示例
def sensor_data_handler():
db.insert(local_node, data) # 本地写入即时生效
# 后台自动同步至云端集群- 离线优先设计:边缘设备在断网时仍可本地读写,数据在网络恢复后自动同步。
- 可靠性保障:采用“无共享”架构,节点故障不影响整体可用性(如电信设备容灾)。
- 混合存储实战:热传感器数据存内存,历史日志存SSD(schema标记
@persistent)。
▶️ 断网时仍可本地操作,网络恢复后自动追补数据。
场景4:资本市场金融交易系统高频交易
- 低延迟处理:进程内架构将延迟压至微秒级,适合订单匹配系统。
- 一致性保证:完整ACID事务(对比NoSQL的最终一致性),确保分布式数据即时一致。
- 性能调优:启用RDMA传输集群同步报文,减少网络开销。
// 创建ACID事务(集群版完整支持)
mco_trans_start(db, MCO_READ_WRITE, &t);
mco_cursor_create(t, &cursor, TradingRecord);
// 高频订单处理(内存数据库避免磁盘I/O瓶颈)
process_order(cursor, order_data);
mco_trans_commit(t);关键配置:
- 启用MVCC并发控制(无锁设计)
- 混合存储配置(SSD持久化日志+内存热数据)
四、性能调优与最佳实践
- 分片策略:按业务键(如设备ID或用户ID)哈希分片,最小化跨节点事务。
- 网络优化:在集群配置中启用RDMA或专用网络通道,提升同步效率。
- 资源管理:监控节点负载,自动重平衡(如峰值时迁移热点数据)。
- 故障恢复:结合事务日志和检查点,确保数据持久性;文档推荐:“eXtremeDB Cluster的‘无共享’架构消除了对共享SAN的依赖。”
五、为什么开发者应选择eXtremeDB Cluster?
eXtremeDB Cluster通过多主节点、进程内设计和精简架构,解决了传统集群的复杂性痛点。开发者可快速部署(30分钟完成)、低成本扩展(商品服务器支持),并在金融、SaaS、物联网等场景中实现高性能与高可靠。实测数据证明其价值:161%吞吐量提升、30% TCO降低。无论您是嵌入式开发者还是企业应用架构师,eXtremeDB Cluster都能让分布式数据库管理变得简单高效。
开发者友好设计
- 零DBA运维:自愈式集群(自动重平衡/故障切换)
- ACID保障:金融级事务一致性(对比NoSQL的最终一致性)
- 开源兼容:提供Python/Java/C++驱动(无缝对接现有系统)
扩展阅读:
eXtremeDB 作为成熟的商用型内存数据库,能够提供稳定、快速、高效的解决方案。
资源获取: 试用下载
技术支持: info@smartedb.com
没有回应